8 Visualizing data
In this chapter, we first discuss the general principles behind choosing the right chart type, and then learn how to create plots in Python using matplotlib.
8.1 Choosing the right chart
Before writing any code, it is worth thinking about what kind of chart best conveys your message. A useful framework (following Zelazny, Say It with Charts) proceeds in three steps:
What is your message? The chart form should not be chosen based on the data alone, but on what you want to say about it. The same table of numbers can lead to very different charts depending on the message. A good chart title states the message, not just the topic — for example, “Pasta recipes doubled on the blog since March” instead of “Recipe overview”.
What type of comparison does your message involve? Every message implies one of five basic comparison types:
- Structure: What share does each part have of the whole? Keywords: share, percentage, proportion. Example: “Italian food accounts for 40% of restaurant visits.”
- Ranking: How do items compare in size or order? Keywords: larger than, smaller than, equal. Example: “Spain is the most popular travel destination.”
- Time series: How does a quantity change over time? Keywords: increase, decrease, trend, fluctuation. Example: “Library visits have grown steadily since January.”
- Frequency distribution: How are values distributed across ranges? Keywords: concentration, distribution, range. Example: “Most hiking trails in the region are between 8 and 15 km long.”
- Correlation: Is there a relationship between two variables? Keywords: relates to, follows, independent of. Example: “There is no connection between cooking time and taste rating.”
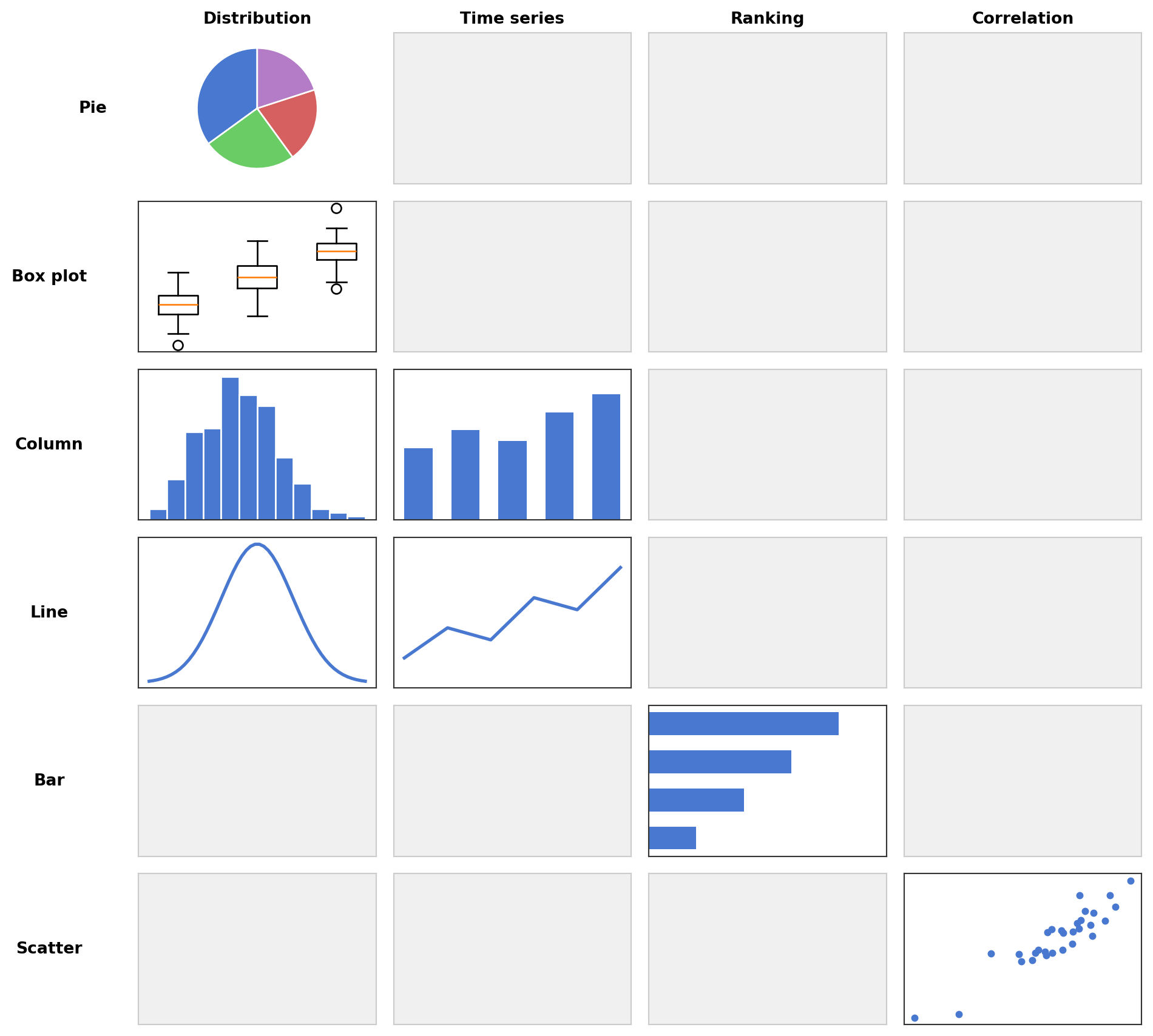
Which chart form fits the comparison type? There are five basic chart forms, and each is best suited for certain comparison types:
- Pie chart: Shows parts of a whole. Best for structure comparisons, but use sparingly — bar charts are almost always more readable.
- Box plot: Best for comparing the distribution of multiple groups side by side (medians, quartiles, outliers). For a single distribution, a histogram (which is a column chart of binned data) is more informative. Violin plots are a refined version of box plots that additionally show the shape of the distribution.
- Column chart (vertical bars): The workhorse for time series and frequency distributions when the number of data points is small (up to about six).
- Line chart: Best for time series and frequency distributions with many data points. Together with column charts, these should cover about half of all charts.
- Bar chart (horizontal bars): Extremely versatile. Best for ranking comparisons.
- Scatter plot: Best for correlation comparisons. Also works for time series and frequency distributions with very many data points.
Beyond these basic forms, additional chart types are frequently used in data analysis, such as heatmaps (colored grids for correlation matrices or similar two-dimensional data).
The following matrix (adapted from Zelazny, Say It with Charts) summarizes which chart form to use for which comparison type. Each cell contains a small example of the recommended chart form.
8.2 Plotting with matplotlib
The standard plotting library in Python is matplotlib. Its pyplot module provides a MATLAB-like interface. Here, plt refers to matplotlib.pyplot.
plt.figure(figsize=(w, h)): create a new figure with given size in inches.plt.xlabel("name"),plt.ylabel("name"),plt.title("name"): add axis labels and title.plt.xticks(positions, labels),plt.yticks(positions, labels): set tick positions and labels on the x/y axis.plt.legend(): show legend. Options includelocfor positioning (e.g.,"upper left"),fontsize, andtitlefor the legend title.plt.show(): display the figure.plt.axvline(x)/plt.axhline(y): draw a vertical / horizontal line across the plot.
import numpy as np
import matplotlib.pyplot as plt
# We will generate some random data here, so we need a random number generator.
rng = np.random.default_rng(0)8.3 Line plots (plot)
A line plot connects data points with straight line segments. It is the standard chart for time series and continuous functions.
plt.plot(x, y, fmt, label=..., linestyle=...): line plot. The optionalfmtis a shorthand format string combining color, marker, and line style, e.g."r*"(red stars),"b--"(blue dashed),"go-"(green circles with solid line). Colors:"r"red,"b"blue,"g"green,"k"black. Markers:"o"circle,"*"star,"s"square,"^"triangle. Thelinestyle(orls) option controls the line appearance:"-"solid (default),"--"dashed,"-."dash-dot,":"dotted.
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x)
plt.figure(figsize=(6, 4))
plt.plot(x, y, label="sin(x)")
plt.axhline(0)
plt.xlabel("x")
plt.ylabel("y")
plt.title("A simple line plot")
plt.show()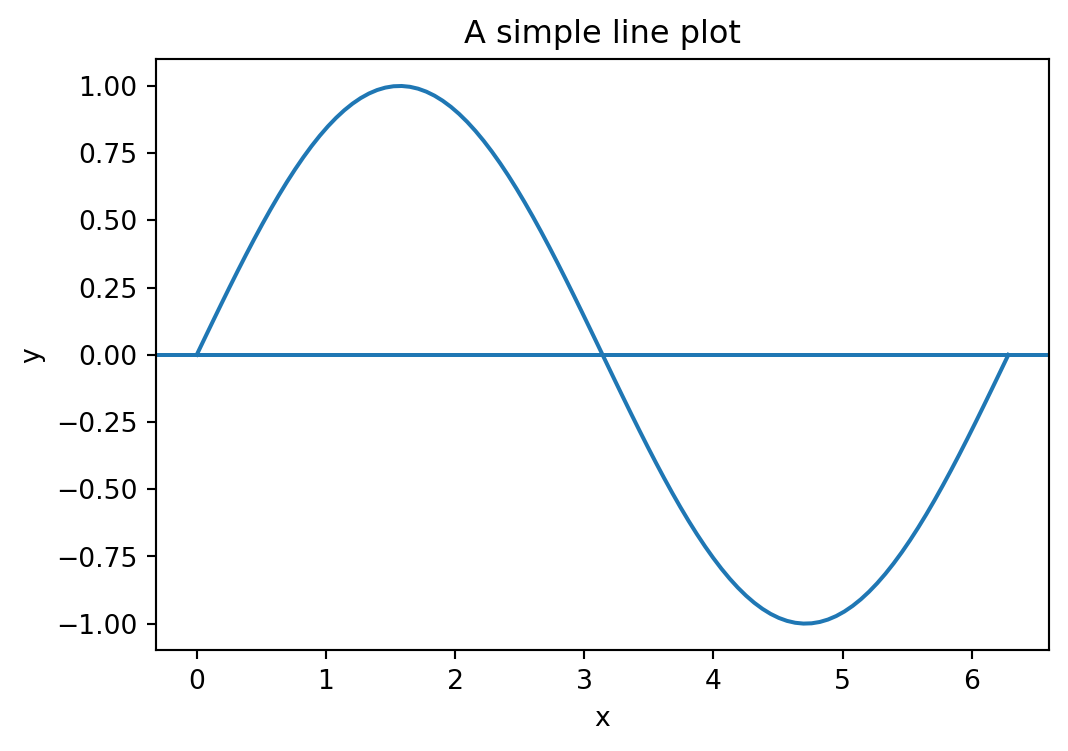
By default, matplotlib draws a rectangular box around the plot. For mathematical function plots, it is often cleaner to place the x- and y-axes at the origin and remove the box. This requires fig, ax = plt.subplots(...) to access the ax.spines object (see also Section 8.8). Each spine is one of the four border lines of the plot area ("left", "right", "top", "bottom").
x = np.linspace(-2, 2, 100)
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(x, x**3 - x, label="$x^3 - x$")
# move the left and bottom spines to x=0 and y=0
ax.spines["left"].set_position(("data", 0))
ax.spines["bottom"].set_position(("data", 0))
# hide the top and right spines
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_title("Axes at the origin")
plt.show()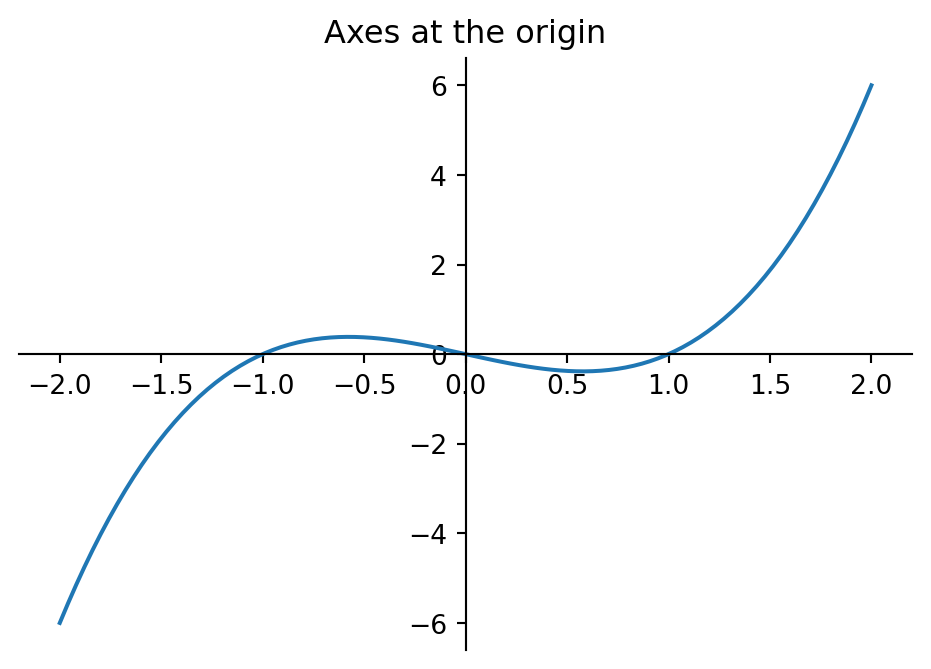
8.4 Pie charts (pie)
A pie chart shows parts of a whole. Use sparingly — bar charts are almost always more readable.
plt.pie(values, labels=...): pie chart. Useautopctto display percentages.
labels = ["Reading", "Cycling", "Cooking", "Gaming"]
values = [30, 25, 20, 25]
plt.figure(figsize=(5, 5))
plt.pie(values, labels=labels, autopct="%1.0f%%")
plt.title("How I spend my free time")
plt.show()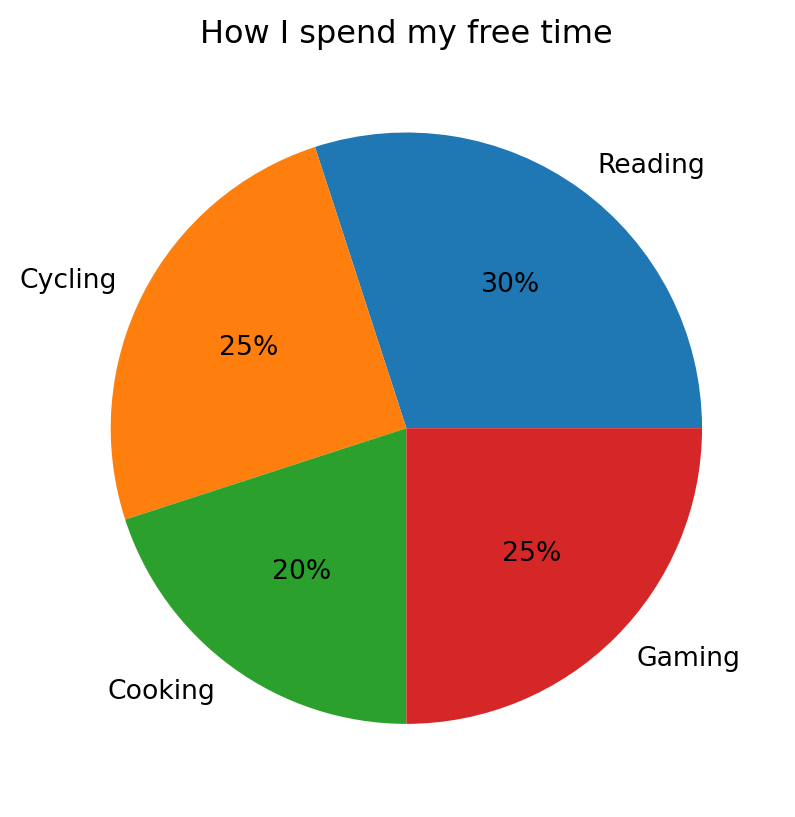
8.5 Bar charts (bar, barh)
Bar charts are the most versatile chart form, suitable for structure, ranking, and comparison tasks. Vertical bars are created with plt.bar, horizontal bars with plt.barh.
plt.bar(categories, values): vertical bar plot. Usebottom=...to stack bars on top of previous ones,yerr=...to add error bars, andcapsize=...to set the width of the error bar caps. Usecolor=...to set the bar color, andalpha=...(0 to 1) to control its transparency.plt.barh(categories, values): horizontal bar plot.
# horizontal bar chart (ranking)
categories = ["Japan", "France", "Italy", "Spain"]
values = [12, 23, 37, 45]
plt.figure(figsize=(6, 4))
plt.barh(categories, values, color="#6acc65", alpha=0.8)
plt.xlabel("Bookings")
plt.title("Spain is the most popular travel destination")
plt.show()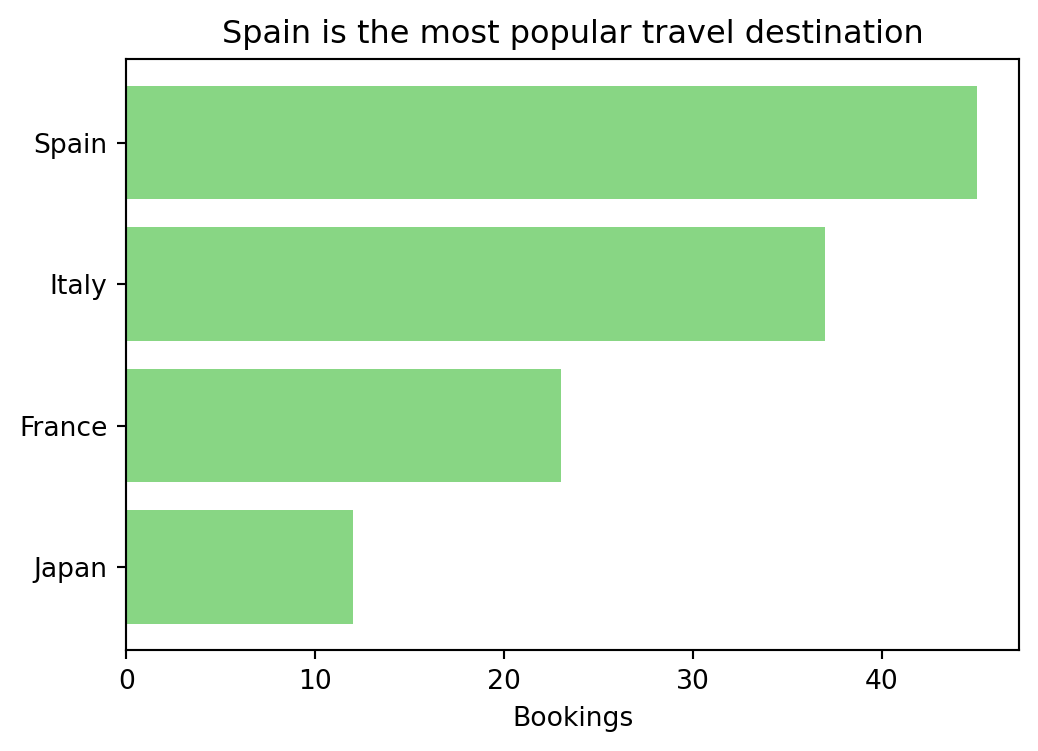
Bar charts become even more useful when comparing multiple series side by side, stacking them, showing differences, or adding error bars. To place two series next to each other, shift the bar positions by the bar width using np.arange.
# survey data: absolute number of people who named each cuisine as favourite
cuisines = ["Italian", "Japanese", "Mexican", "Indian"]
adults_abs = [70, 40, 50, 40] # 200 adults surveyed
kids_abs = [36, 8, 24, 12] # 80 kids surveyed# grouped bar chart: compare percentages
# (so group sizes don't distort the picture)
adults_pct = [a / sum(adults_abs) * 100 for a in adults_abs]
kids_pct = [k / sum(kids_abs) * 100 for k in kids_abs]
x = np.arange(len(cuisines))
width = 0.35
plt.figure(figsize=(7, 4))
plt.bar(x - width/2, adults_pct, width, label="Adults")
plt.bar(x + width/2, kids_pct, width, label="Kids")
plt.xticks(x, cuisines)
plt.ylabel("Preference (%)")
plt.title("Food preferences differ between adults and kids")
plt.legend()
plt.show()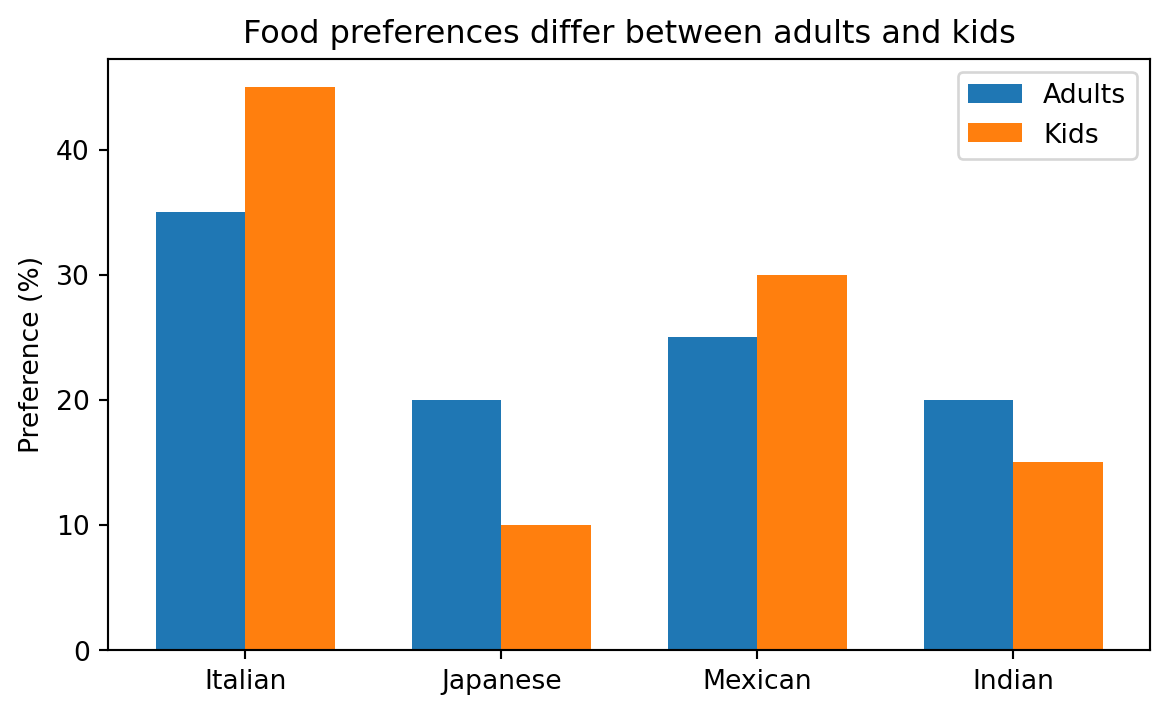
# stacked bar chart: absolute numbers show the total count per cuisine
plt.figure(figsize=(7, 4))
plt.bar(cuisines, adults_abs, label="Adults (n=200)")
plt.bar(cuisines, kids_abs, bottom=adults_abs, label="Kids (n=80)")
plt.ylabel("Number of people")
plt.title("Italian food is the overall favourite")
plt.legend()
plt.show()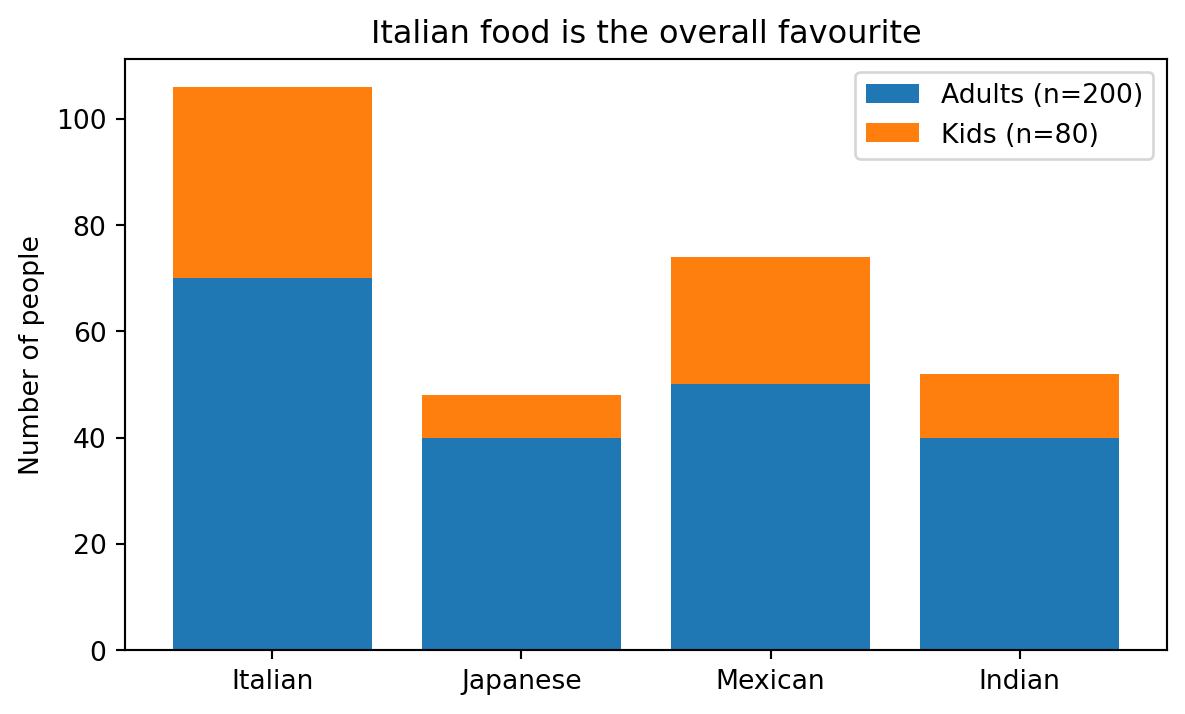
# difference chart: horizontal bars going left and right from a center axis
diff = [a - b for a, b in zip(adults_pct, kids_pct)]
colors = ["#4878cf" if d >= 0 else "#d65f5f" for d in diff]
plt.figure(figsize=(7, 4))
plt.barh(cuisines, diff, color=colors)
plt.axvline(0, color="black", linewidth=0.8)
plt.xlabel("Difference in preference (Adults − Kids, pp)")
plt.title("Kids prefer Italian more, adults prefer Japanese")
plt.show()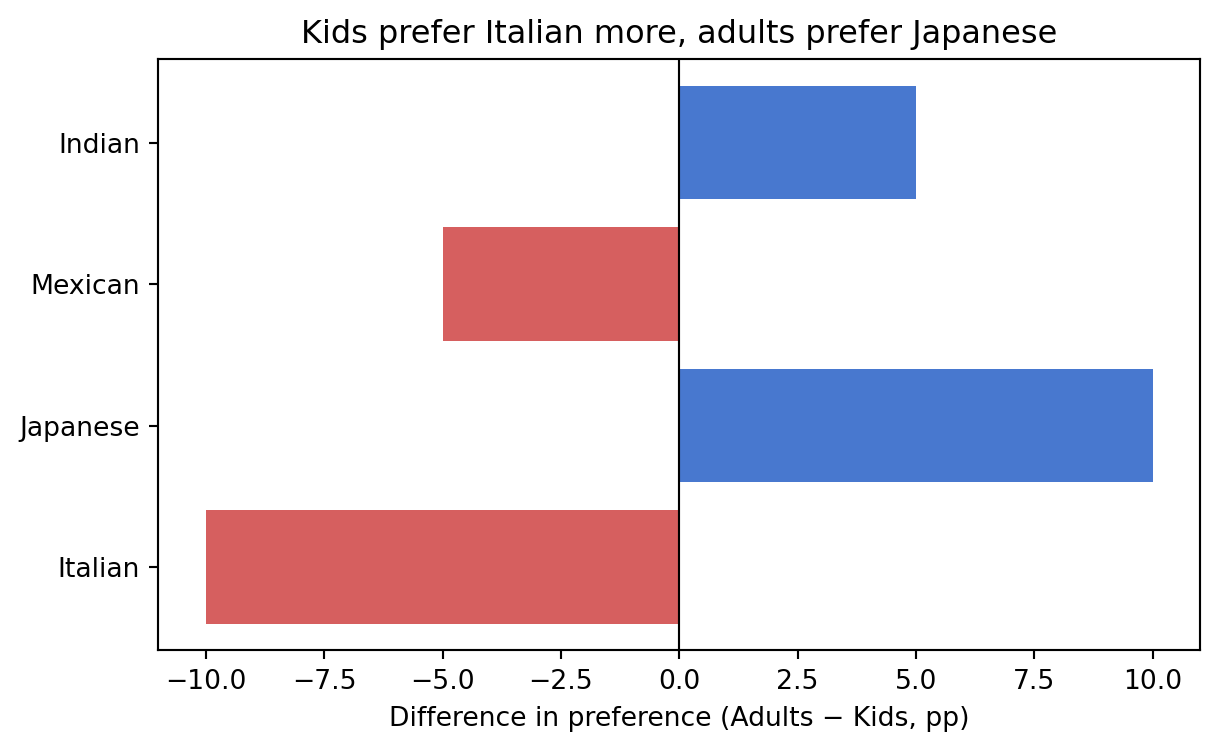
You can add error bars to a bar chart to show uncertainty (e.g., standard deviations or confidence intervals) using the yerr parameter.
# bar chart with error bars
sports = ["Swimming", "Running", "Cycling", "Yoga"]
participants = [45, 38, 30, 25]
std_dev = [5, 7, 4, 6]
plt.figure(figsize=(6, 4))
plt.bar(sports, participants, yerr=std_dev, capsize=5, color="#4878cf")
plt.ylabel("Participants")
plt.title("Swimming is the most popular sport")
plt.show()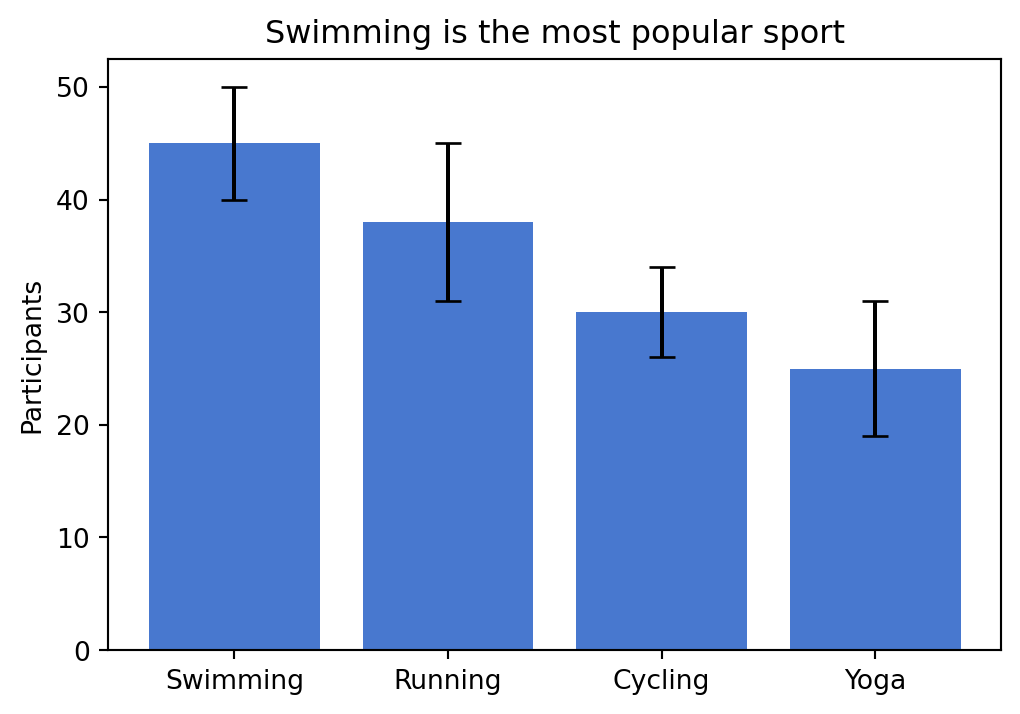
8.6 Histograms (hist)
A histogram groups numeric data into bins and shows the frequency or density of each bin. It is the standard chart for frequency distributions.
plt.hist(data, bins=..., density=...): histogram. Usedensity=Trueto normalize to a probability density,alpha=...(0 to 1) to make the bars semi-transparent, andrwidth=...(0 to 1) to control the bar width relative to the bin width (default 1.0, i.e. no gaps).
data = rng.normal(loc=5, scale=2, size=500)
plt.figure(figsize=(6, 4))
plt.hist(data, bins=30, density=True, alpha=0.7)
plt.xlabel("x")
plt.ylabel("density")
plt.title("Histogram of normally distributed data")
plt.show()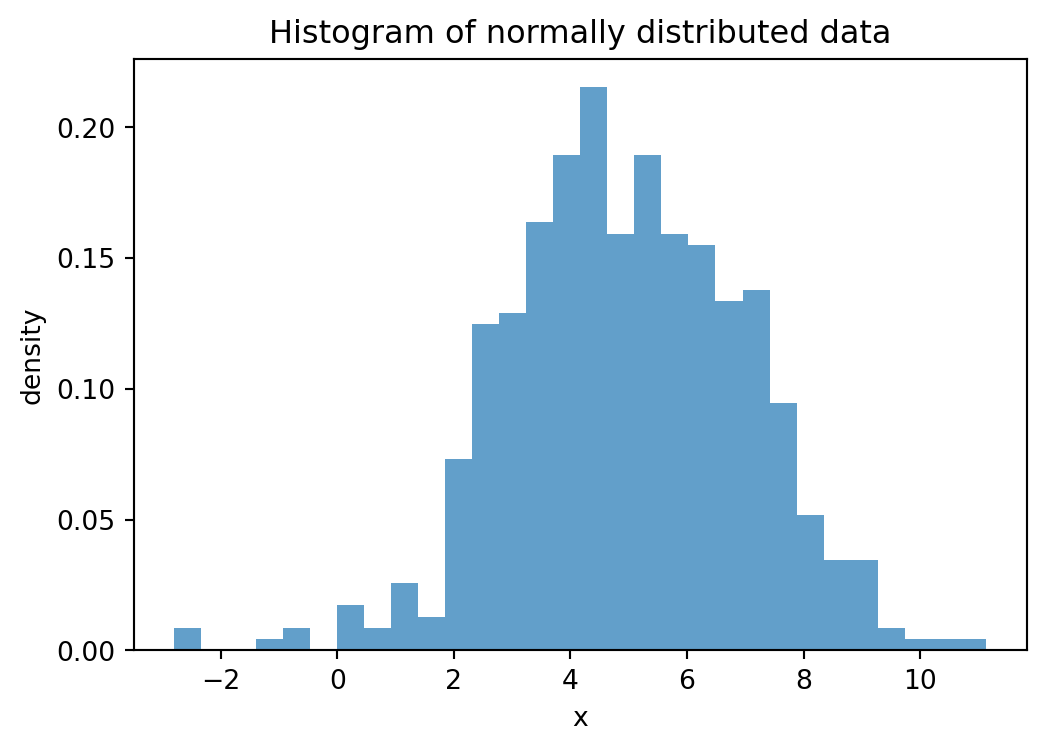
8.7 Box plots (boxplot)
A box plot summarizes the distribution of a dataset. The box spans from the first quartile (Q1, 25th percentile) to the third quartile (Q3, 75th percentile), so it contains the middle 50% of the data. The line inside the box marks the median (Q2, 50th percentile). The whiskers extend from the box to the most extreme data points that are still within 1.5 times the interquartile range (IQR = Q3 − Q1) from the box edges. Points beyond the whiskers are shown as individual dots and considered outliers. Box plots are especially useful for comparing distributions across groups.
plt.boxplot(data_list, tick_labels=...): box plot. Pass a list of arrays to compare multiple groups, andtick_labelsto label them.
categories = ["A", "B", "C", "D"]
data_groups = [rng.normal(loc=m, size=50) for m in [0, 1, 2, 3]]
plt.figure(figsize=(6, 4))
plt.boxplot(data_groups, tick_labels=categories)
plt.title("Box plot")
plt.show()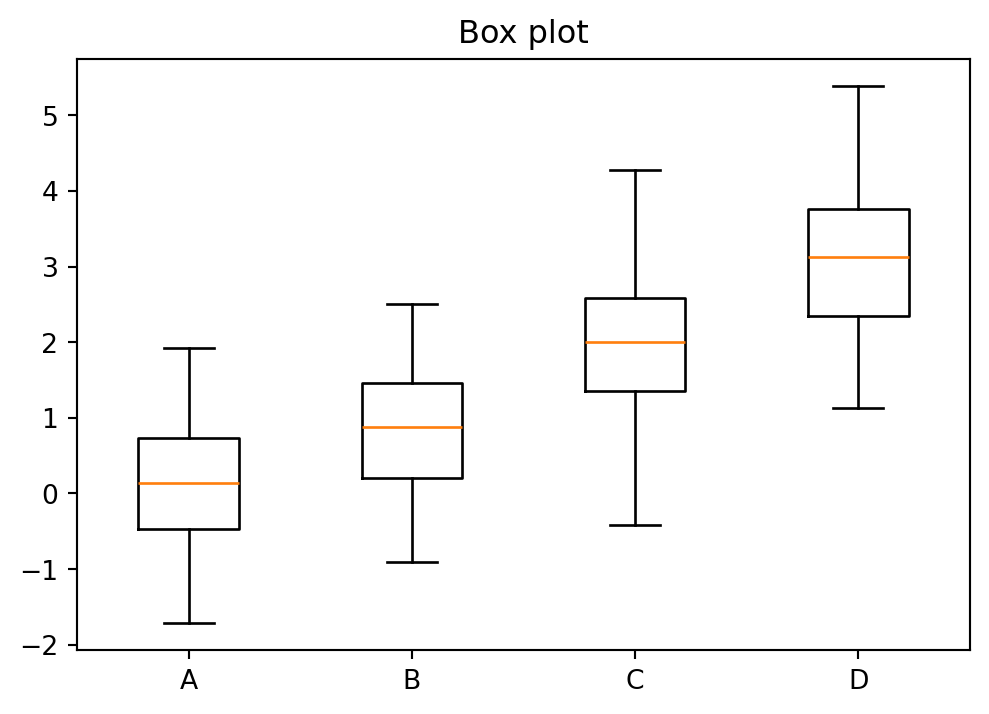
8.8 Subplots (subplots)
Subplots allow placing multiple plots in a single figure. Each subplot is an independent axes object that supports the same methods as plt but prefixed with ax. or axes[i]. (e.g., axes[0].plot(...), axes[0].set_title(...)).
fig, axes = plt.subplots(nrows, ncols, figsize=...): create a grid of subplots. For a single subplot, usefig, ax = plt.subplots(figsize=...).plt.tight_layout(): automatically adjust spacing so labels do not overlap.ax.spines["side"].set_position(("data", value)): move a spine (the border lines of the plot area) so that it crosses the axis atvalue. The"side"can be"left","right","top", or"bottom".ax.spines["side"].set_visible(False): hide a spine entirely.
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].plot(np.linspace(0, 1, 50), np.linspace(0, 1, 50)**2)
axes[0].set_title("y = x^2")
axes[1].plot(np.linspace(0, 1, 50), np.sqrt(np.linspace(0, 1, 50)))
axes[1].set_title("y = sqrt(x)")
plt.tight_layout()
plt.show()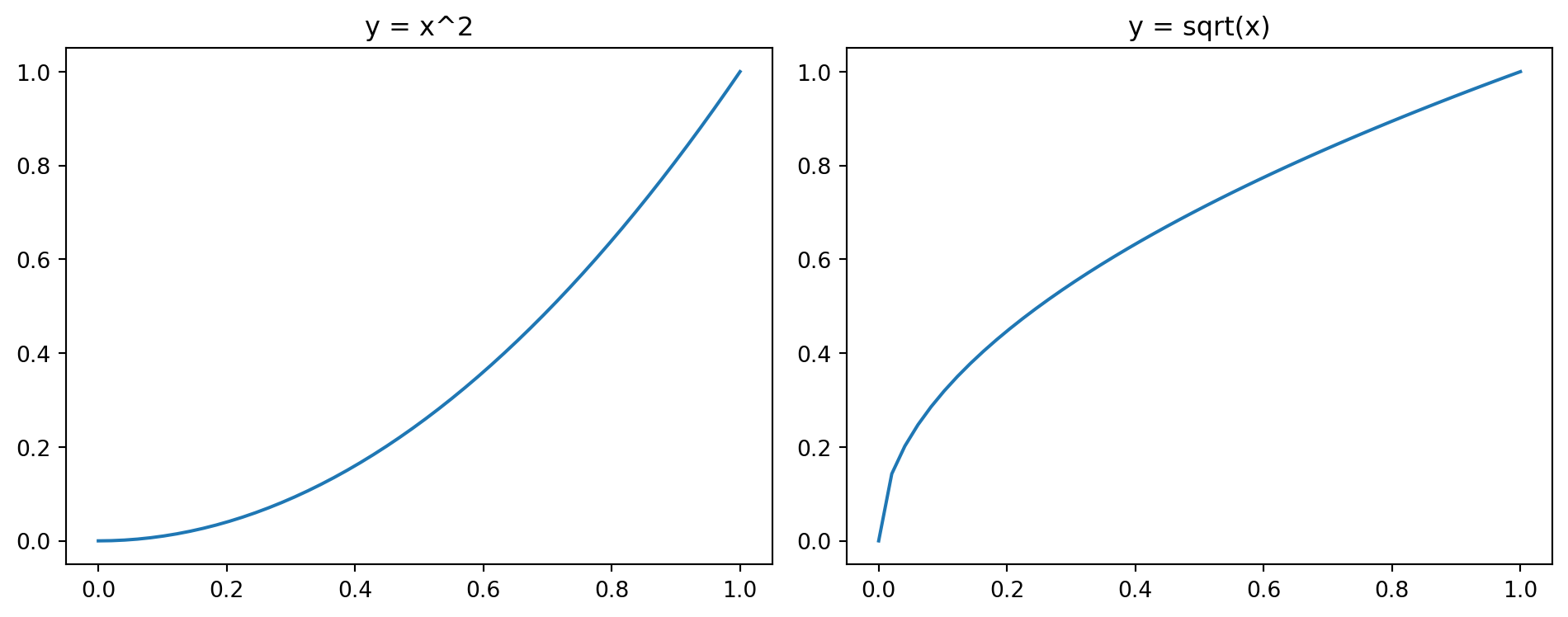
8.9 Scatter plots (scatter)
A scatter plot shows individual data points without connecting them. It is the primary chart for correlation comparisons.
plt.scatter(x, y, s=..., label=...): scatter plot (sis marker size).
x = rng.normal(size=100)
y = 2 * x + 0.5 * rng.normal(size=100)
plt.figure(figsize=(6, 4))
plt.scatter(x, y, s=20)
plt.xlabel("x")
plt.ylabel("y")
plt.title("A scatter plot")
plt.show()
8.10 Heatmaps (imshow)
A heatmap displays a matrix of values as a grid of colored cells. It is useful for visualizing correlation matrices, confusion matrices, or any two-dimensional data where patterns emerge from color. A related function is plt.contourf, which draws filled contour lines for data given on a 2d grid (see Section 9.4 for an example).
plt.imshow(matrix, cmap=...): display a matrix as a colored grid. Usevmin/vmaxto fix the color range. Common colormaps:"viridis"(default),"coolwarm"(diverging, blue to red),"hot","gray","Blues","RdYlGn".plt.contourf(X, Y, Z, levels=..., cmap=...): draw filled contour lines for valuesZon a grid defined byXandY. Uselevelsto control the number of contour levels.plt.colorbar(label=...): add a color bar to the current plot, with an optional label.np.corrcoef(data, rowvar=False): compute the correlation matrix of the columns ofdata(see Section 9.1 for more on correlation).
# heatmap of a correlation matrix
data = rng.normal(size=(100, 4))
data[:, 1] += 0.8 * data[:, 0] # introduce correlation between columns 0 and 1
labels = ["A", "B", "C", "D"]
corr = np.corrcoef(data, rowvar=False)
plt.figure(figsize=(5, 4))
plt.imshow(corr, cmap="coolwarm", vmin=-1, vmax=1)
plt.xticks(range(4), labels)
plt.yticks(range(4), labels)
plt.colorbar(label="Correlation")
plt.title("Correlation matrix")
plt.tight_layout()
plt.show()
8.11 Exercises
All exercises in this section use the World Bank Indicators API (see Section 7.9). The following helper code fetches population data for a list of countries over a range of years. You may reuse and adapt it.
import requests
def wb_population(countries, date_range="1960:2023"):
"""Fetch total population from the World Bank API.
countries: list of ISO3 codes, e.g. ["DEU", "FRA", "ITA"]
date_range: year range as "start:end"
"""
codes = ";".join(countries)
url = f"https://api.worldbank.org/v2/country/{codes}/indicator/SP.POP.TOTL"
response = requests.get(url, params={
"date": date_range, "format": "json", "per_page": 5000
})
data = response.json()[1]
df = pd.DataFrame([{
"country": e["country"]["value"],
"iso3": e["countryiso3code"],
"year": int(e["date"]),
"population": e["value"]
} for e in data if e["value"] is not None])
return df.sort_values(["iso3", "year"])Exercise 1 Use wb_population to fetch the world population from 1960 to 2023 (ISO3 code "WLD"). Plot the result as a line chart with the year on the x-axis and population on the y-axis. Add a title that states the trend you observe.
# Exercise 1Exercise 2 Fetch the 2023 population for these countries: Germany (DEU), France (FRA), Italy (ITA), Spain (ESP), Poland (POL). Display the result as a horizontal bar chart, sorted by population. Which country is the most populous?
# Exercise 2Exercise 3 Fetch population data from 1960 to 2023 for Germany, France, and Italy. Plot all three as line charts in the same figure with a legend. Convert the year column to a datetime using pd.to_datetime(df["year"], format="%Y") and use it as the x-axis.
# Exercise 3Exercise 4 A survey asked 80 students about their favourite season. The results: Spring 18, Summer 30, Autumn 20, Winter 12. Display the results as a pie chart with percentages. Then create a second version as a horizontal bar chart. Which chart is easier to read?
# Exercise 4Exercise 5 Generate four groups of random data: rng.normal(loc=m, scale=s, size=50) with (m, s) = (5, 1), (6, 2), (5.5, 0.5), (7, 1.5). Display them as a box plot. Which group has the largest spread? Are there outliers?
# Exercise 5Exercise 6 Generate 500 samples from a normal distribution with mean 170 and standard deviation 10 (think: heights in cm). Plot a histogram with 25 bins and density=True. Overlay the theoretical density curve using np.linspace and stats.norm.pdf (you may import from scipy import stats). Experiment with rwidth=0.9 and alpha=0.7.
# Exercise 6Exercise 7 Using the data from Exercise 3, compute the population growth per decade (1960s, 1970s, …, 2010s) for each country. Display the result as a grouped bar chart with decades on the x-axis and one bar per country.
# Exercise 7Exercise 8 Fetch a second indicator — GDP per capita (NY.GDP.PCAP.CD) — for at least 20 European countries for the year 2022. Also fetch their population. Create a scatter plot of GDP per capita (x-axis) vs. population (y-axis). What do you observe? Hint: adapt the wb_population function by changing the indicator code.
# Exercise 8Exercise 9 Using the population data from Exercise 3, compute the correlation matrix of the three countries’ populations (hint: use pivot to reshape the DataFrame so that each country is a column, then use np.corrcoef or df.corr()). Display the result as a heatmap. Why are the correlations so high?
# Exercise 9